An Intro to Transfer Learning
The Problem
In order to train state-of-the-art deep learning models, often a lot of data and a lot of compute is necessary for training. For many applications, it can be hard to obtain such a large volume of data and pay for the necessary compute resources.
The Solution
Transfer Learning is the process of taking a pre-trained model and tailoring it to a more specific or related task. The general idea is that a lot of the weights and features learned by large models pre-trained on lots of data, could be useful for solving other more specific tasks with a bit of fine-tuning. For example, large image classification models like ResNets trained on difficult image classification datasets like ImageNet-21k which has over 21,000 classes of images. In order to perform well on such difficult tasks, these models need to be quite large and expressive and they need to be trained on lots and lots of data.
The general idea is that with an expressive enough model, lots of important high-level features can be extracted from the data by applying complex and often non-linear functions to the data (this is essential what a neural network does). These high level features can then easily be used to classify images.
An Example Using a CNN
A Convolutional Neural Network (CNN) is a particular kind of neural network that is often used for imaging tasks in deep learning. Let’s take an example with an image which is represented as a tensor with three dimensions — $x, y, c$ where $x, y$ are the spatial dimensions and $c$ is the channel dimension (i.e $c = 3$ for an RGB image). Now we can take some smaller predefined images and slide them around the bigger input and multiply and accumulate the values as we do it to produce a smaller image. You might be able to imagine that where the two images are very similar, the output value will be larger. These smaller images are known as filters or kernels and they can be used to pick out features in the input image in this way. For example, we might have a kernel that looks like a vertical line and another that looks like a horizontal line. The output images from sliding these kernels around the input image will have larger values where we found vertical and horizontal lines, respectively. For those of you with a mathematical background you might be thinking this sounds more like cross-correlation than convolution and you would be right. That is exactly what the operation is and Convolutional Neural Network is somewhat of a misnomer in this way.
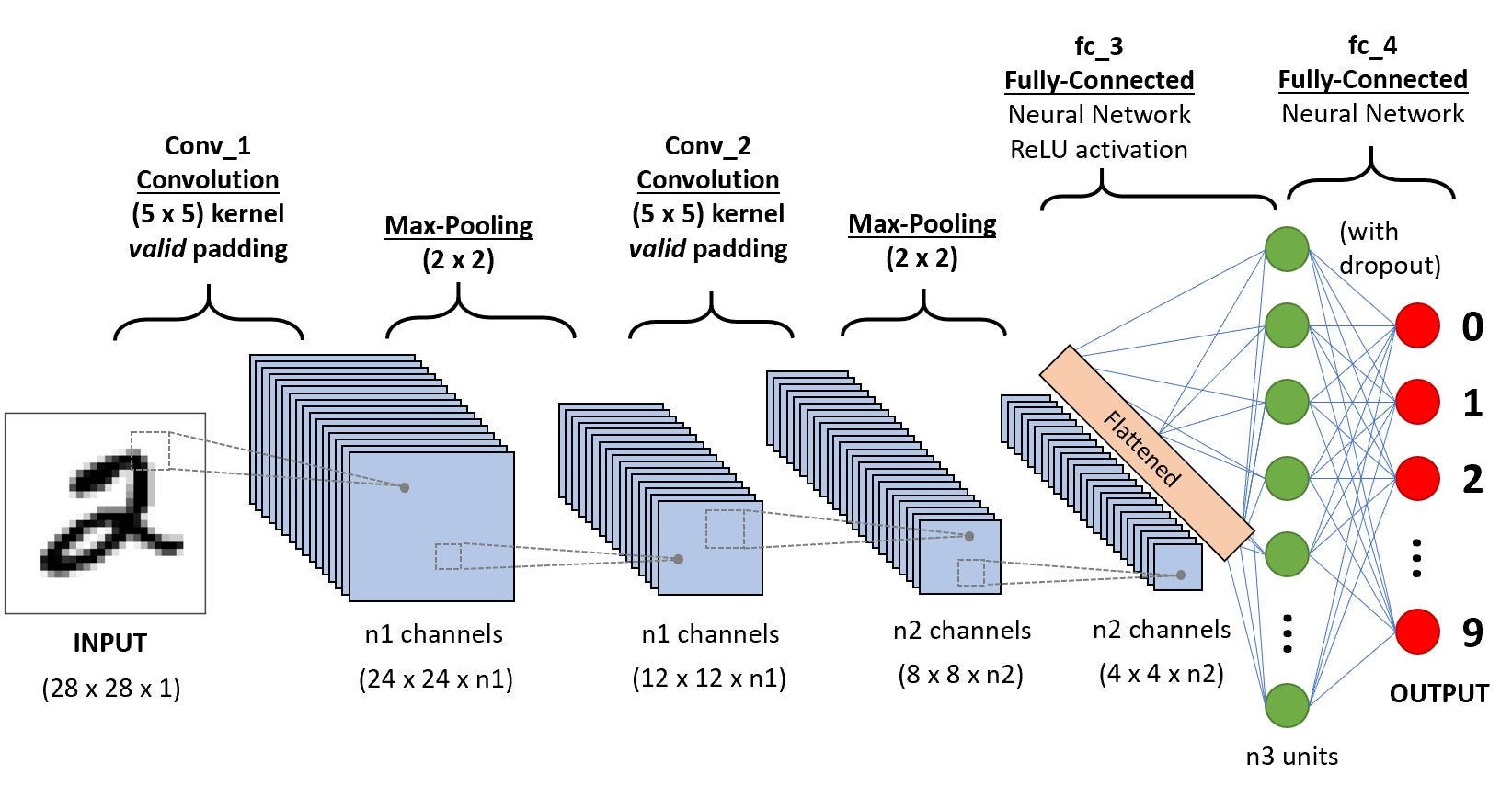 The structure of a CNN
The structure of a CNN
Now if we define a lot of these different kernels and use them for cross-correlation over the input image and then define more and apply them over the output images from the previous cross-correlation step e.t.c with the right filter you can imagine we can get more and more high level features. For example, the first layer might have edges, the next might have corners and the next might have simple shapes e.t.c until we have some fairly complex features. A CNN usually also has some pooling layers and potentially some other operations it applies during training (i.e dropout or batch normalisation) however understanding that it is used for feature extraction via cross-correlations is a fairly good simplification of the process.
 Some examples of features extracted using filters in a CNN
Some examples of features extracted using filters in a CNN
So here is a picture:

Now what is it a picture of? Hopefully if you aren’t visually impaired you said a cat. Now if I asked you, how do you know it is a cat. After a bit of thinking you might say, well it has eyes, whiskers, pointy ears and fur all over it’s body. In fact, if I had given you that description, you could probably guess I am taking about a cat. So we can imagine that after applying all of these cross-correlation steps, our CNN has some kind of similar representation of features like this. The interesting and powerful part about using deep learning to do this is that we never explicitly tell it what these kernels are. It learns the kernels that are able to extract the most useful features. This is great because in traditional computer vision techniques this was an extremely difficult process that often required specific domain knowledge to design. Even with this knowledge it was not always easy to find the right kernels.
At the end it is then common to flatten the output feature map and add a simple Multi-Layer-Perceptron which basically forms a complex non-linear function that takes these features as inputs and produces a one dimensional tensor as an output. Usually a soft-max activation function is then applied to scale the outputs into probabilities that add to 1 and this is your probability for each class (if you were doing classification).
How to Take Advantage of Pre-trained State-of-the-Art Models
So as stated before, the major issue with training really high performing models is that it is often difficult to get enough data and/or compute to solve your specific task. BUT, these general pre-trained models like ResNet, which is a CNN with residual connections (see the paper linked in the first section for more details on this), are able to classify over 21,000 classes of images with a fairly high degree of accuracy — surely some of the features they learned would be applicable to your task. It turns out this is quite likely and so if you use their model but just add your own output layer, you can use all of the features that the state-of-the-art model has been able to extract but apply your own function at the end of it to interpret these features in a way that is useful for your specific task. This is known as transfer learning and not only is it often much more computationally cheap but it is also much less effort since you do not need to design the model from scratch. It may also be that even with a really good architecture, you do not have enough data for the model to learn these more intricate features, however the state-of-the-art pre-trained model was able to because of all of the extra data it was trained on. Therefore, in many cases, the transfer learning approach can outperform models strictly designed for the more specific purpose that are only trained on the problem-specific data.
Comments powered by Disqus.